외부 API 다루는 방법(feat. Rate Limit)

TLDR
- Muze라는 음악 SNS를 개발하고 있다.
- 노래 정보 검색 기능이 필요한데, 데이터가 부족한 상황이라 검색 결과가 좋지 않다.
- 필요한 데이터를 바로 검색 후 수집할 수 있도록 외부 API를 활용한다.
- 이 외부 API에 문제가 생기면, 앱에도 문제가 생긴다. 그리고, API에는 Rate Limit이 걸려있어서 요청 수가 제한된다.
- 외부 API의 의존성을 최소화하기 위해 fallback으로 사용할 API를 여러 개 두고, Token Bucket 알고리즘을 사용하여 요청을 분산시킨다.
서비스를 개발하면서 A-Z까지 전부 다 구현하기란 어렵다. 구현의 난이도 뿐만 아니라 효율면에서 부적절하다. 그래서 우리는 외부 API를 호출한다. 원하는 기능을 편리하게 사용이 가능하다. 한 가지 문제점이라면, 외부의 의존성이 생김으로써 내부의 문제가 아닌 외부의 문제로 서비스의 결함이 발생할 수도 있다는 점이다. 예를 들어, 쇼핑몰 서비스에서 외부 결제 시스템의 문제로 상품 결제가 이루어지지 않는다면, 실질적인 손해로 이어질 수 있다.
진행중인 사이드 프로젝트 Muze는 음악 취향을 공유하는 웹서비스이다. 자신이 좋아하는 노래를 게시하고 공유하는 기능이 메인 서비스다. 이 서비스를 위해서는 노래 정보들을 데이터베이스에 저장하고 검색하는 기능이 필요한데, 프로젝트의 규모상 '검색이 가능한 노래'의 범위를 정하기가 애매했다. 물론 적당히 구할 수 있는 노래들을 읽어와서 저장하는 방법도 있겠지만, 실제 사용자들이 사용하기에 매끄러운 서비스를 만들고 싶었다.
그래서 생각한 방법은 사용자가 검색 시에 음악 플랫��폼(Spotify, Shazam 등)의 검색 API를 활용해서 결과를 리턴해준다. 음악 정보가 서버 내에 당장 없더라도, 정보를 반환해줄 수 있게 되는 것이다. 하지만 이런 처리는 외부 API에 대한 서버의 의존성이 생기게 된다. 우리 서버가 정상적으로 동작한다고 해도, Spotify의 서버에 문제가 생기면 고스란히 그 문제가 우리 서버의 문제로 돌아온다.
외부 API를 활용하는 것은 이미 결정된 사항이기 때문에 이 상황에서 내릴 수 있는 차선의 선택을 하는 것이 중요하다. Spotify 서버에 문제가 생긴다면, Shazam 서버를 활용하는 건 어떨까? 두 플랫폼 모두 문제가 생길 일은 극히 드물 것이다. 인풋 형식과 아웃풋 형식을 맞춰서 추상화된 RequestHandler 클래스를 작성한다.
from abc import ABC, abstractmethod
class RequestHandler(ABC):
def __init__(self, api_client):
self.api_client = api_client
@abstractmethod
def search(self, keyword, category):
return 노래정보
class SpotifyAPIRequestHandler(RequestHandler):
...
class ShazamAPIRequestHandler(RequestHandler):
...
class YoutubeAPIRequestHandler(RequestHandler):
...
 노래 검색을 위해 활용할 API가 세 개나 생겼다.
그럼 이제 들어오는 요청들을 이 API들에게 어떻게 분배해줄지 설정해주어야한��다. 요구사항은
노래 검색을 위해 활용할 API가 세 개나 생겼다.
그럼 이제 들어오는 요청들을 이 API들에게 어떻게 분배해줄지 설정해주어야한��다. 요구사항은
- 결과가 나오지 않을 경우(response.status_code !=200), 다른 API로 요청을 넘긴다.
- 각각의 API의 Rate Limit을 초과하지 않는다.
- 사용자 경험을 고려하여 최대한 빠른 속도로 결과를 리턴해준다. 로 정리가 가능하다.
이 요구사항을 충족시키는 방법은 Token Bucket알고리즘을 활용하여 Rate Limiting을 적용하는 방법이다.
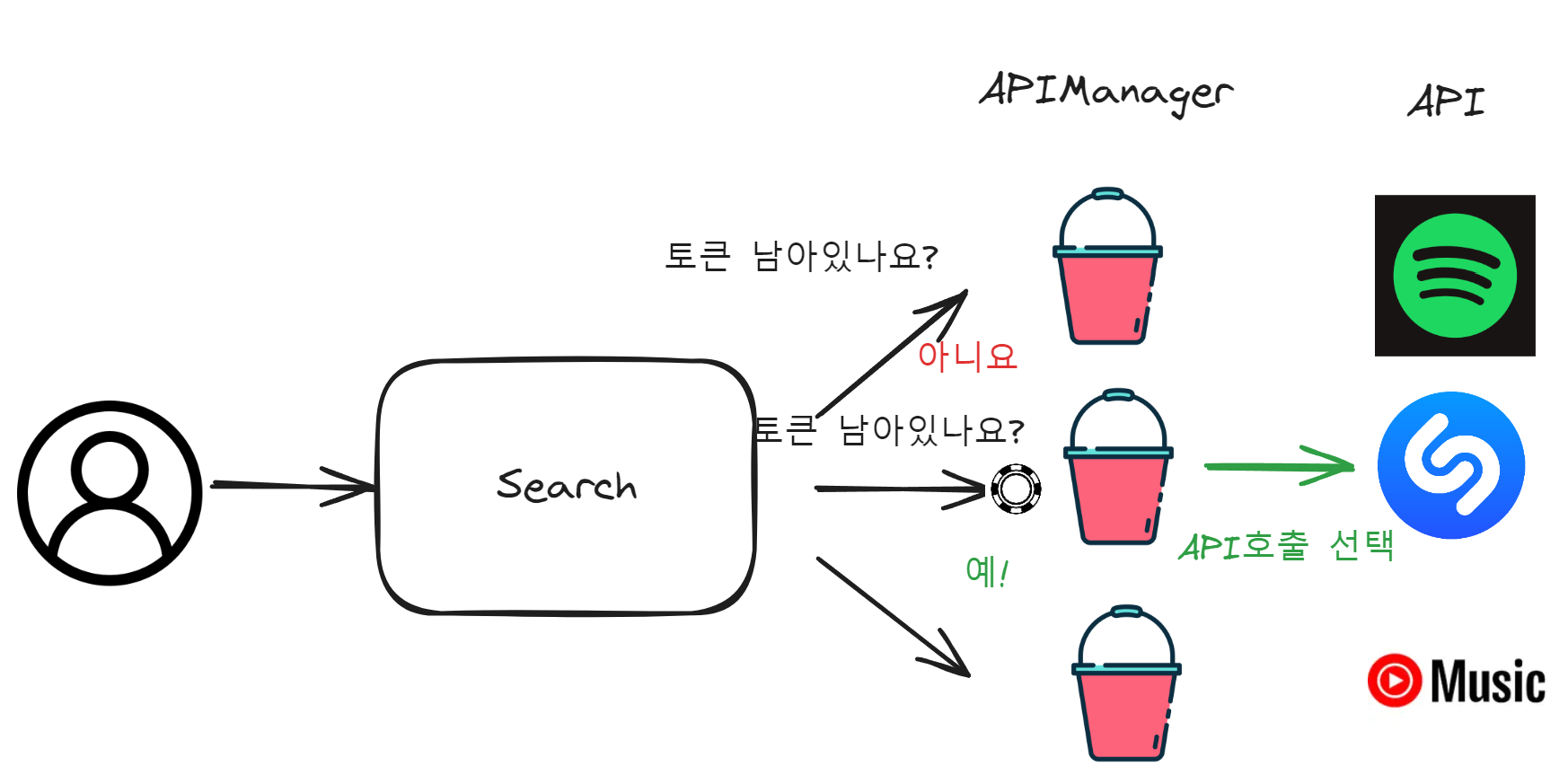
토큰 버킷 알고리즘은 토큰을 기록하여 사용량을 조절한다. 토큰은 시간에 따라 일정량씩 채워지고, 등록된 함수의 호출 시점에 토큰을 사용한다. 만약 시간당 채워지는 토큰보다 더 많은 호출이 이뤄지면 잠시동안 함수 호출이 멈추는 원리이다.
TokenBucket 클래스와 이를 관리하는 APIManager 클래스를 만들어 토큰 버킷 알고리즘을 구현해준다. 각 API당 할당된 Rate Limit 정보를 기반으로 rate(초당 버킷에 채워지는 토큰 수)과 capacity(버킷이 담을 수 있는 토큰의 최대수)을 설정한다.
그리고, 서버 접속 사용자 수에 따라 프로세스가 추가된다는 점을 상기해야한다. 프로세스 간의 APIManager 인스턴스는 독립적인데, API 호출은 공유하기 때문에 이를 인스턴스 간 정보들을 공유할 수 있도록 설정해주어야한다. 인메모리의 Redis를 사용해서 rate, capacity, token 정보를 공유하도록 설정한다.
rate, capacity 설정을 위해서 API 문서에서 Rate Limit에 대한 정보들을 살펴보았다. Spotify같은 경우에는 Rate Limit을 30초동안 쌓인 요청수를 기준으로 잡는다는 이야기만 있고 최대 요청량은 적혀있지 않았다(내가 못 찾았을수도...). 그래서 concurrent.future 모듈을 활용하여 30초동안 보낼 요청 수를 조정하여 실험한 후 최대 요청량을 가늠하였다.
# num_worker=1,2,3,4,5, ...,9,10
[{'num_requests': 158, 'num_success': 158, 'num_failures': 0}, {'num_requests': 302, 'num_success': 301, 'num_failures': 1}, {'num_requests': 533, 'num_success': 307, 'num_failures': 226}, {'num_requests': 774, 'num_success': 311, 'num_failures': 463}, {'num_requests': 992, 'num_success': 342, 'num_failures': 650}, {'num_requests': 1208, 'num_success': 356, 'num_failures': 852}, {'num_requests': 1474, 'num_success': 414, 'num_failures': 1060}, {'num_requests': 1659, 'num_success': 390, 'num_failures': 1269}, {'num_requests': 1973, 'num_success': 405, 'num_failures': 1568}, {'num_requests': 2243, 'num_success': 402, 'num_failures': 1841}]
스포티파이 API는 30초동안 대략 300 - 400개 정도의 요청을 받아준다. 대체 API인 Shazam과 Youtube도 비슷한 수량의 요청을 받아준다고 할 때, 대략 우리 서버는 30초동안 1000개의 검색 요청을 처리할 수 있다는 이야기이다. 이 얘기는 Muze 앱 운영 중에 1001명의 유저가 검색을 한 번씩 하는 경우가 30초의 시간동안 한 번이라도 발생할 경우, 다운타임이 발생할 수도 있다는 이야기이다. (물론 300명의 유저가 생길지 안 생길지조차 모르는 상황이긴 하지만, 30초동안 검색 한 번은 너무 짜다. 보통 한 유저당 한번 이상의 검색을 한다.)
이런 문제는 검색이 호출될 때 백그라운드로 해당 노래 정보를 데이터베이스에 저장하는 식으로 구성한다면, 시간이 지남에 따라 이런 문제들은 해결될 수 있을 거라고 생각했다. 한 번 이상 검색된 정보는 데이터베이스에서 호출되는 방식이기 때문에, 시간이 지날수록 외부 API에 대한 의존도가 낮아질 것이라고 기대했다. 여기에다가 추가적으로 백그라운드 스케쥴러로 최신곡에 대한 크롤링을 주기적으로 수행한다면, 외부 검색 API의 의존성을 최소화하고, 괜찮은 사용자 경험을 제공해줄 수 있게 된다.
이번 글에서는 Rate Limit이 설정되어있는 API를 다루기 위해 고려해야할 부분들과 안정적으로 처리할 수 있는 Rate Limit 기법에 대해서 알아보았다. 검색 기능은 Muze에서 꽤 중요한 기능이다. 이런 중요한 기능을 외부 API에 의존해야한다는 점이 고민되긴 했지만, 부족한 데이터를 다 커버할 수 없는 초기 개발 상황에서 차선의 선택이 필요했다. 외부 API에 의존하되, 운영 시 생길 수 있는 의존성을 최소한으로 줄이고, 데이터가 쌓임에 따라 그 의존성을 아예 없앨 수 있다면, 꽤 괜찮은 시나리오라고 생각한다.