DEVIEW 2023 "ML/AI 개발자를 위한 단계별 Python 최적화 가이드라인"을 보고

영상 링크 : ML/AI 개발자를 위한 단계별 Python 최적화 가이드라인
유튜브 추천 동영상에 흥미로운 영상이 올라왔다.
"ML/AI 개발자를 위한 단계별 Python 최적화 가이드라인"
네이버 파파고 OCR팀 문주혁 님의 DEVIEW 2023 영상이다.
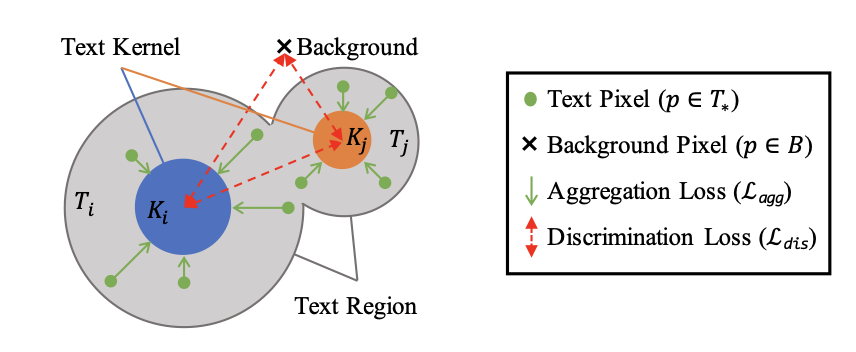
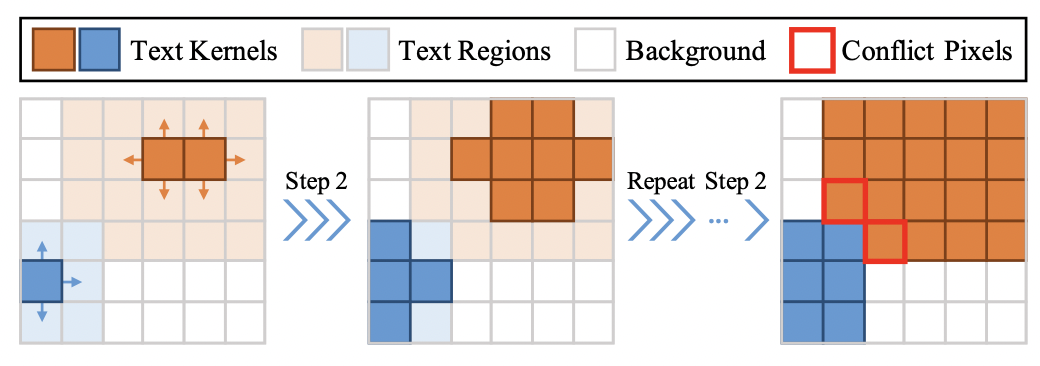
OCR, 이미지에서 텍스트를 탐지하는 단계에서, 텍스트 박스 갯수가 많아지면 속도가 느려지는 이슈를 어떻게 해결했는지에 대해 이야기한다. 전에 일했던 회사에서 똑같이 겪었던 이슈였기 때문에 집중해서 봤다. 영상을 보고 내 나름대로 문제 해결을 위해 발표자분이 어떤 식으로 접근했는지 정리해보았다. 기술적인 부분보다는 문제를 해결하기 위한 자세에 초점을 두고 글을 작성했다.

- 문제 배경
- 문제 해결 방법
- 내가 시도해볼 것(Takeaway)
문제 배경
파이썬은 딥러닝 모델을 개발하기 위한 생태계가 잘 구성되어있다. GPU를 활용하여 딥러닝 모델을 학습/평가/서빙할 수 있는 pytorch, tensorflow 등 여러 프레임워크들과 고차원의 행렬 데이터들을 처리할 수 있는 pandas나 numpy와 같은 라이브러리들이 있��다.
문제는 파이썬이 다른 언어들보다 느리다는 점이다. 모델 개발이 끝난 후, 딥러닝 모델의 앞단과 끝단에서 데이터를 처리하는 전처리나 후처리 또는 다른 부분들에서 속도가 느린 걸 발견할 수도 있다.
데이터 사이언티스트들은 보통 CS 백그라운드가 다른 개발자들보다 강한 편은 아니다. (물론 케바케겠지만) 내 첫번째 컴퓨터 언어는 파이썬이고, 비교적 최근에야 C나 C++ 같은 언어에 관심을 갖게 되었지만, 개인적으로 생각하기에 코드를 보고 '이런 부분을 고치면 조금 더 속도가 개선되겠는걸? 아 여기서 병목현상이 발생하는구나' 같은 컴퓨터 내부 동작 원리를 건드리는(또는 컴퓨터 내부 동작 원리를 알아야만 가능하다고 생각한) 생각은 많이 해보지 못한 것 같다.
그래도 완성된 딥러닝 알고리즘이 작동하는 방식을 제일 잘 이해하는 개발자는 모델을 담당한 데이터 사이언티스트 본인일 것이고, 속도가 개선되어야만 한다면 그건 데이터 사이언티스트의 임무일 것이다.
영상에서는 요새 핫한 모델 최적화 기법, 상당히 높은 지식 수준을 요구하는 고난이도 기술 대신, 우리가 시도해볼 수 있는 것 그리고 실질적인 결과물을 낼 수 있는 방법에 대해서 이야기한다.
문제 해결방법
측정 => {문제 개선방법 시도 => 측정 => 결과 분석} x repeat => 문제 개선
측정
문제를 해결하기 위해서는 우선 문제가 있다는 사실부터 인정해야한다는 말이 있다.
'속도가 느리다'라는 이슈를 해결하기 위해, 우선 속도 프로파일링을 진행한다. 문제 해결을 위한 가장 첫번째 단계는 문제 개선 여부를 측정할 수 있는 지표 설정이다.
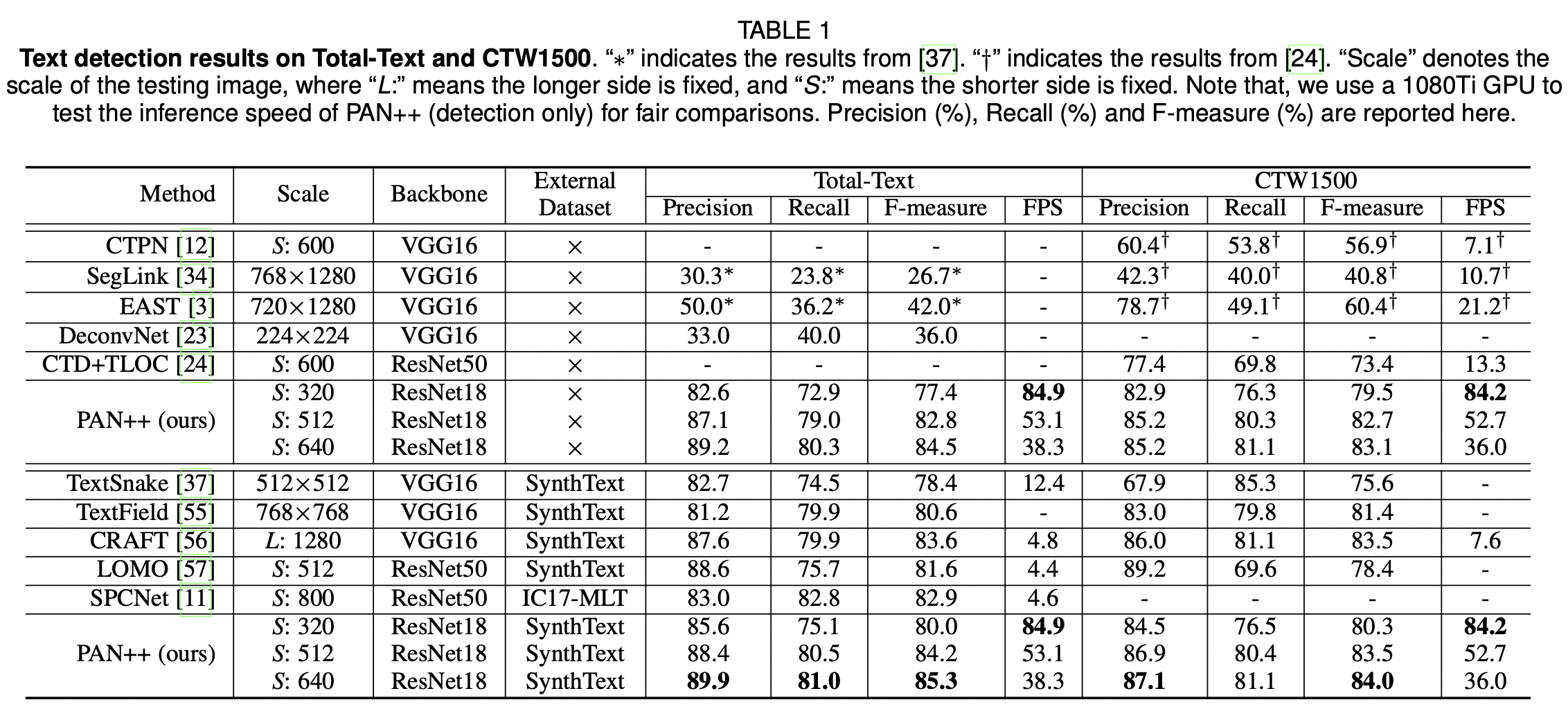
파이썬에서 제공하는 timeit함수도 있지만, 코드 곳곳에 일일히 입력해야한다는 단점이 있다. timeit 대신 line_profiler라는 라이브러리를 사용했다고 한다. 전체 코드에 대해서 줄줄이 얼마만큼의 시간이 걸렸고, 몇 퍼센트의 비중을 차지하는지 알 수 있다고 한다.
문제 개선방법 시도
해결해야하는 문제가 '속도가 느리다'에서 '우리 코드 중 어느 부분이 특히 느리다'로 문제의 범위가 좁아졌다. 이제는 문제를 개선할 수 있는 방법들을 나열한다. 무작정 이 방법, 저 방법 해보자 보다는 여러 측면/레벨에서 시도해볼 수 있는 것들을 체계화하는 것이 중요하다. 영상에서는 속도 개선을 위해 python level, semi-c level, c/c++ level 세 가지로 나누어 접근했다.

문제 개선방법 - python Level
문제 해결 방법들을 나열했다면, 가장 시도해보기 쉬운 것부터 시도해본다. 실패했을 때 비용이 적고, 가볍게 직접 시도해보면서 해결하고자 하는 문제가 조금 더 구체화된다는 장점이 있다. 문제 정의 시에 알지 못했던 부분에 대해 새롭게 알게 된다거나, 새로운 해결방법들을 추가해볼 수도 있다.
numpy나 opencv는 c와 c++로 작성된 라이브러리로 파이썬에서 작동할 수 있는 최적 속도를 어느정도 보장받는다. 그렇다고 해서 해당 라이브러리로 작성된 코드가 작성할 수 있는 최적의 속도라는 의미는 아니다. 개선할 수 있는 부분이 있을지도 모른다.
다시 한번, 문제 해결 방법은 여러가지가 있겠지만, 가장 시도해보기 쉬운 것부터 시도하는 것이 중요하다. numpy나 opencv에서 개선할 수 있는 부분을 찾으라고 해서, 안에 구동되는 동작원리를 파악하고, c++ 코드를 재작성하라는 의미가 아니다. 가장 쉽게 시��도해볼 수 있는 방법은 '같은 라이브러리 내에서 코드 문맥에 조금 더 적합한 함수가 있을 수 있다. 더 알맞은 함수로 변경해보자'이다.
문제 개선방법 - Semi-c Level
파이썬 속도 개선을 위해 검색을 하다보면 항상 나오는 키워드가 있다. cython이나 numba. 결론만 말하자면, "pure python, 즉 라이브러리를 사용하지 않은 파이썬 자체 코드일 경우 눈에 띄는 성능 개선을 확인할 수 있지만, 다른 언어로 작성되어 이미 빠른 라이브러리를 사용할 경우, 그다지 좋은 성능 개선은 기대하기 힘들다"고 한다. 여기서 내가 생각하기에 중요한 부분은 '좋다고 해서 써봤는데?"라는 생각으로 시도한 방법에 대한 대응 방식이다.
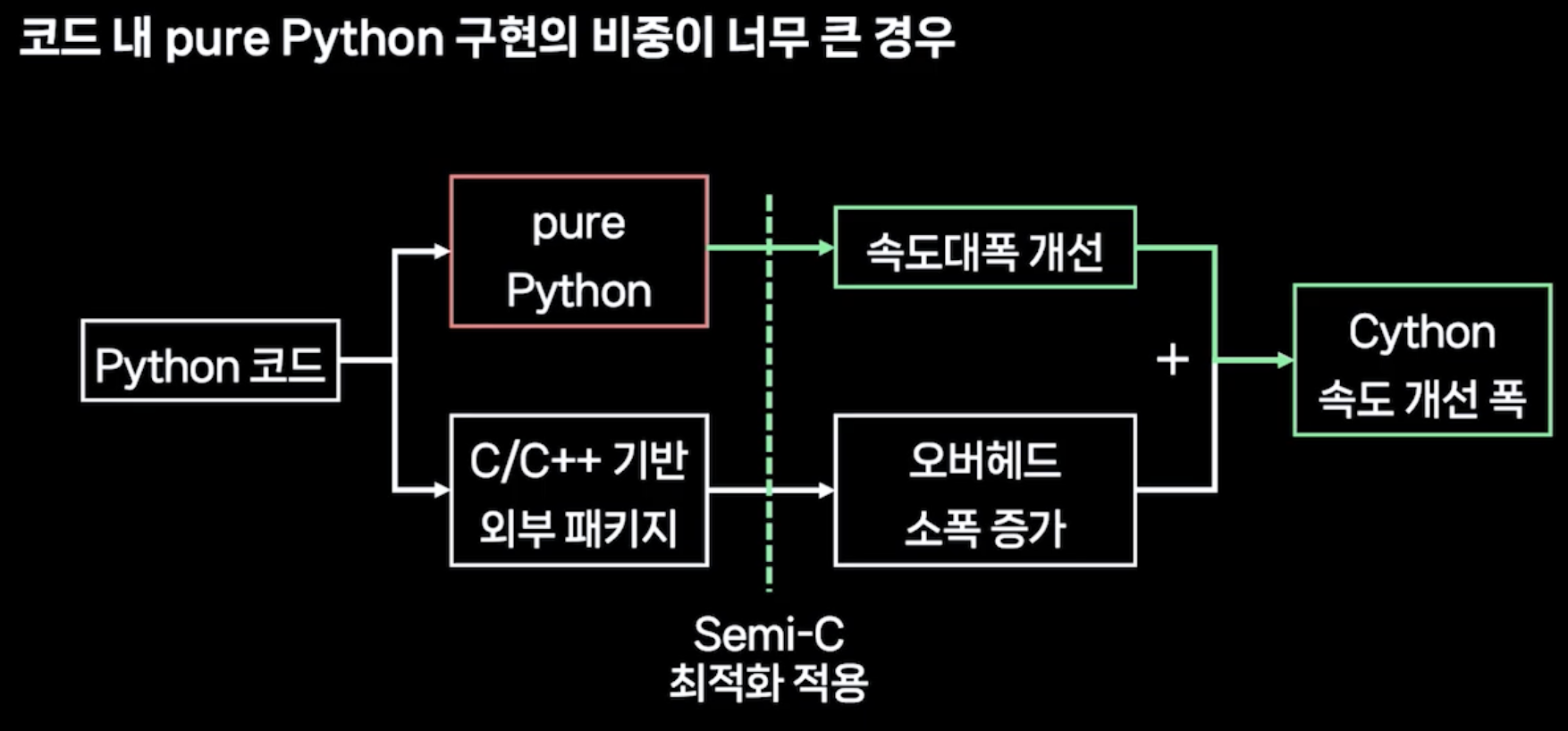
시도한 방법은 생각보다 결과가 좋을 수도 있고, 좋지 않을 수도 있다. 하지만, 결과의 퀄리티를 떠나, 결과를 분석하는 단계는 항상 있어야한다. cython이나 numba를 시도하는 방법에 있어서, '파이썬 자체 코드 => 성능 개선 우수, 라이브러리 코드 => 성능 개선 미미'라는 결론에 다다르기까지는 여러번의 실험과 분석이 있었을 것이다(추측이긴 하지만). 한 번에 이런 결론에 다다르면 정말 좋겠지만, 배경지식이 없는 상태에서 실험 후에 명료한 결론을 내리는 것은 생각보다 쉬운 일이 아니라고 생각한다. 여러번 걸릴 수도 있겠지만, 각 시도마다 결과를 분석하고, 나름의 결론과 경험치를 쌓아서 실용적인 결론에 다다르는 것이 중요하다.
('시도해봤는데 결과가 잘 안나왔다. 이 방법은 구리다' 같은 결론이 아니라, 영상에서처럼 '이 방법은 이럴 때는 잘 작동하지만, 저럴 때는 잘 작동하지 않을 수도 있으니 참고하세요.' 같은 실용적인 결론이다.)
문제 개선방법 - C/C++ Level
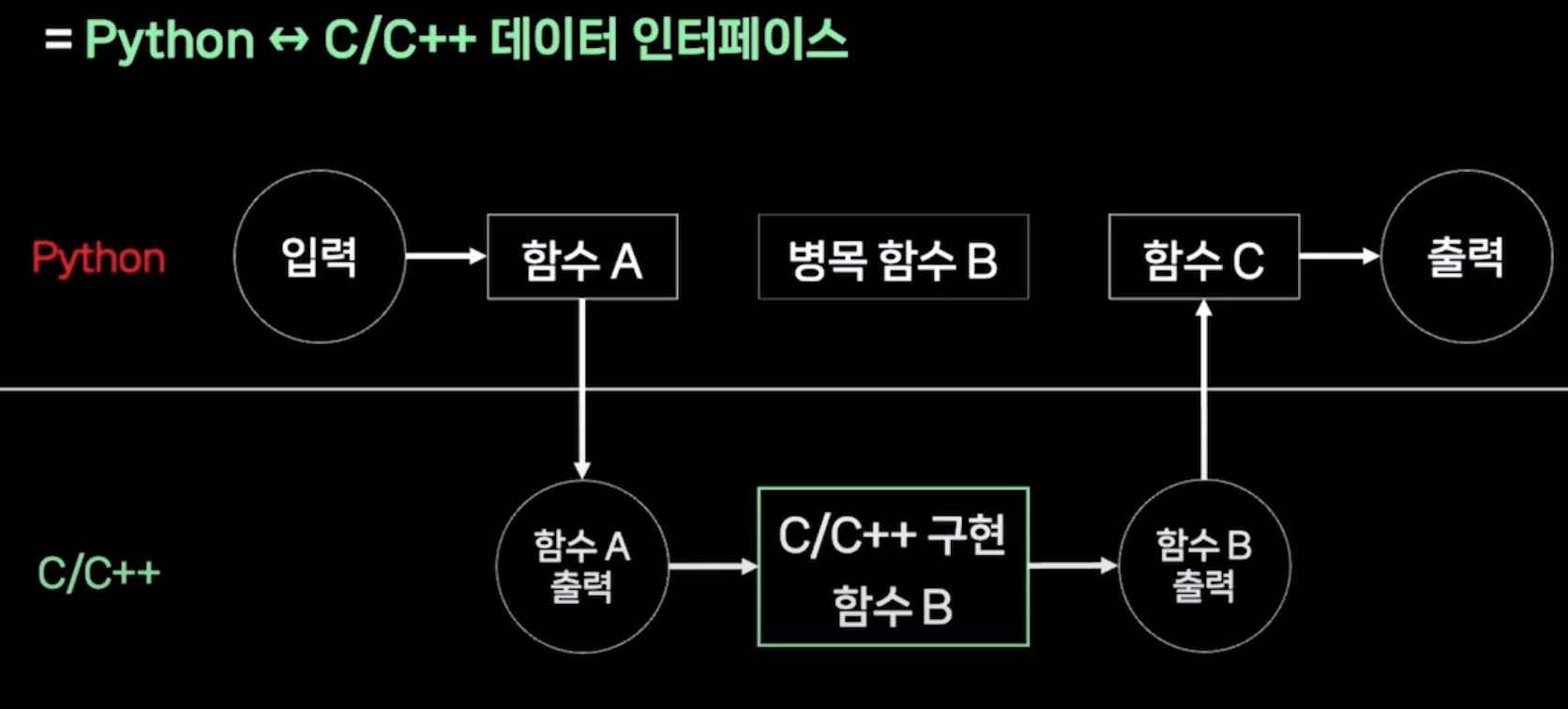
만약 C/C++ implementation을 적용하기로 결정했다면, '시도해보기 쉬운 것부터 시도' 원칙이 다시 한번 적용된다. 전체 코드를 바꾸는 대신, 시간이 오래 걸리는 병목 함수를 찾고 해당 부분만 C/C++ 구현을 적용한다. 여기서 내가 생각하기에 중요한 부분은 두 가지였다.
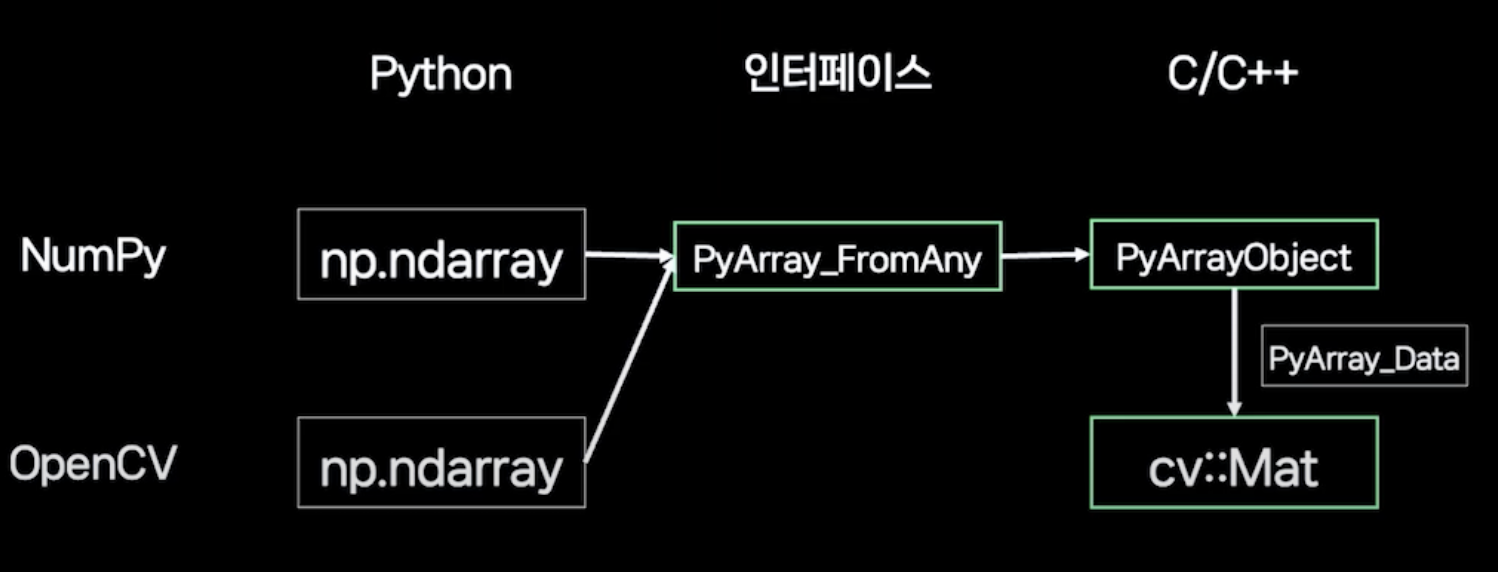
첫째는 새로운 코드 적용이 항상 공식 문서에 제공된 example과 같이 딱 들어맞지는 않을 것이기 때문에, 내 상황에 맞게 활용하는 유연성이 필요하다는 점이다. 영상에서는 numpy의 ndarray를 C에서 지원하는 cv::Mat 형식으로 변환하기 위해 Numpy C api에서 제공하는 PyArray_FromAny와 c++에서 제공하는 PyArrayObject를 거친다. '어? 내가 원하는 기능을 지원 안 하네?'하고 바로 포기해버리기보다는 조금 돌아가더라도 어떻게 해결할 수 있을지 고민해볼 필요가 있다.
두번째는 직접 해봐야 안다는 점이다. 위에서 언급했��다시피, numpy와 opencv 같은 라이브러리들은 C/C++로 구현되어 있기 때문에 어느정도 최적의 속도를 보장한다. 그렇다면, 해당 라이브러리로 작성한 코드 속도가 무조건 C/C++로 구현한 속도와 동일할까? 아니다. 영상에서는 라이브러리로 작성한 파이썬 코드를 동일한 로직의 C/C++로 변환했을 때, 50%에 가까운 속도 향상을 얻었다고 한다. 개발을 하다보면 이론과는 다른 결과가 발생하기도 한다. 이론을 맹신하지말고, 직접 시도해보는 과정이 필요하다.
(문제 해결을 위해 돌아서 풀어가는 과정(workaround)에 길을 잃지 않기 위해서는 기초지식과 다루고 있는 문제의 본질에 대한 이해가 필요하다. 또, 이론이 전부가 아니다. 직접 시도해보는 과정이 필요하다.)
내가 시도해볼 것들(Takeaway)
영상을 보고 배운 점을 정리하자면 다음과 같다.
- 최적화를 위해 컴퓨터 내부 동작 원리를 알아야만 가능한 것은 아니다.
- 문제 해결은
측정 -> 해결 방법 시도 -> 측정 -> 결과 분석의 반복으로 이루어진다. - 문제 개선 여부를 측정할 수 있는 지표 설정하기
- 문제 범위를 좁히기
- 여러 측면/레벨에서 시도해볼 수 있는 것들을 체계화하기
- 각 시도마다 결과를 분석하고, 나름의 결론과 경험치를 쌓아서 실용적인 결론 내리기
- 새로운 방법을 내 상황에 맞게 활용하는 유연성 기르기
- 기초지식 갈고닦기
- 해결하고자하는 문제를 이해하기
- 이론을 맹신하지 말고, 직접 시도해보기









![[출처] : CRAFT: Character-Region Awareness For Text detection](/assets/images/craft_example-9f69274551a53f1d2727a0e974dbf7c2.gif)