The New Code

최근 OpenAI의 Sean Grove가 진행한 “The New Code”라는 스피치를 듣고 많은 걸 느꼈습니다. LLM의 발전에 따라 변화할 소프트웨어의 미래와 그 변화의 양상을 소프트웨어의 본질에 근거해 상상하고 구체화해볼 수 있었습니다.
※ 이 글은 해당 영상을 기반으로 한 요약이며, 일부 해석은 제 개인적인 의견이 반영되어 있을 수 있습니다.
🔍 소프트웨어의 본질: 코드는 전부가 아닙니다
우리는 흔히 소프트웨어의 중심이 ‘코드’라고 생각하지만, 실제로 코드가 만들어지기까지의 전 과정을 들여다보면 진짜 핵심은 '커뮤니케이션' 에 있음을 알 수 있습니다.
무엇을 만들지, 왜 만들지, 어떻게 만들지, 그리고 만들어진 것이 의도한 대로 작동하는지까지. 이 모든 것은 사람 사이 또는 사람과 인공지능 사이에 구조화된 커뮤니케이션을 통해 이루어집니다.
🤖 LLM 시대의 전환점: 컴파일러에서 모델로
LLM이 본격적으로 등장하면서, 프로그래머가 코��드를 직접 작성하지 않고 모델에게 자연어로 설명하는 방식(바이브 코딩)이 점차 늘어나고 있습니다.
LLM이라는 매개체를 통해 사람의 의도를 컴퓨터에게 입력하는 것은 사실 새로운 컨셉이 아닙니다. 우리는 항상 코드를 통해 우리의 의도를 컴퓨터에게 전달하고 있었습니다. 개발자가 의도를 담아 코드를 작성하면, 컴파일러가 이를 번역해서 컴퓨터가 수행할 수 있는 기계어로 전환합니다. LLM은 단지 코드를 사람의 언어(자연어)로 확장했을 뿐이라고 볼 수 있습니다.
그렇다면, 여기서 한 가지 고민해볼 점은 지금까지처럼 코드를 보존하고 관리하는 것이 여전히 적절한 방식인지, 아니면 프롬프트나 명세와 같은 인간의 의도를 담은 표현을 중심으로 보존해야 하는지에 대해서입니다.
**사람이 작성한 코드** - [컴파일러] -> 기계어
**사람이 작성한 프롬프트와 명세** - [LLM] -> 코드
이런 논리라면, 컴파일러가 작성한 기계어가 아니라, 의도가 좀 더 명확한 프롬프트와 명세(specification) 를 보존하는 것이 더 타당하지 않을까요?
Sean Grove는 이 프롬프트와 명세를 '모델 스펙' 이라고 정의합니다.
📄 모델 스펙: AI가 이해하는 인간의 언어
Sean Grove는 앞으로의 소프트웨어 개발에서 가장 중요한 자산은 코드가 아니라 명확한 명세(model spec) 가 될 것이라고 말합니다.
모델 스펙은 다음과 같은 특징을 가집니다:
• Specs compose: 조합 가능하며 모듈화될 수 있습니다.
• Specs are executable: 실행 가능한 명령 구조를 가집니다.
• Specs are testable: 테스트가 가능하며 검증 기준을 포함할 수 있습니다.
• Specs have interfaces: 외부와 소통할 수 있는 인터페이스를 가집니다.
이러한 스펙은 단순한 설명을 넘어서, 사람의 의도를 일관되게 전달할 수 있는 추상화된 형식입니다. 말 그대로 자연어가 새로운 코드(The New Code)인 셈입니다. LLM 시대에는 이 명세가 자연어로 작성되기 때문에, 기존 코드보다도 명확한 의사소통의 도구로 기능할 수 있습니다.
⚖️ 법조 시스템과 스펙 기반 개발의 유사성
모델 스펙의 개념은 법조 시스템과도 매우 유사합니다.
사회가 사람의 행동을 정렬하기 위해 헌법과 법률을 만들듯, AI 모델 역시 명확한 스펙을 통해 행동을 정렬 하게 됩니다.
• 헌법 · 법률 (written text) → written specification 모델이 따라야 할 기준이 되는 문서. 명확하고 모호하지 않아야 함.
• 개정 조항 (amendments) → pull request / version bump 명세를 업데이트하는 절차. 코드의 버전 관리와 유사.
• 판례 (case law) → regression tests 기존 동작을 유지하는 테스트. 과거의 기준을 반복해서 검증함.
• 사법적 검토 (judicial review) → grader model 모델의 결과물이 명세에 부합하는지 자동 평가.
• 권한 계층 (supremacy clause / hierarchy) → spec hierarchy 명세 간 우선순위를 설정하는 구조. 충돌 방지를 위함.
• 집행 기관 (enforcement by executive) → reinforcement loop 명세에 맞는 행동을 하도록 학습을 유도하는 강화 루프.
이러한 비교는 AI 엔지니어의 역할이 단순한 기술 구현자 를 넘어, AI 시스템의 ‘입법자’ 혹은 ‘정책 설계자’ 로 진화하고 있음을 보여줍니다.
🧭 직업의 본질은 ‘정렬’입니다
Sean Grove의 스피치는 정렬(alignment) 에 대한 통찰로 마무리됩니다.
우리의 직업은 각기 다르지만, 본질적으로는 ‘무언가를 정렬시키는 일’을 수행 하고 있습니다. 정렬이란 단순히 "일치시키는 것"이 아닙니다. 의도를 명확히 정의하고 최소 법칙 아래에서 구성원들(컴포넌트들)이 자유롭지만 의도한대로 동작할 수 있도록 설계 하는 일 입니다. 아마 이 과정을 얼마나 명확히 할 수 있는지가 미래의 핵심 역량 이 될 것이라고 조심스럽게 예측해봅니다.
역할별 정렬 대상을 정리해본다면 다음과 같습니다.
프로그래머
- 정렬 대상: 컴퓨터(실리콘)
- 정렬 수단: 코드 명세 (code spec)
제품 매니저(PM)
- 정렬 대상: 팀
- 정렬 수단: 제품 명세 (product spec)
법률가
- 정렬 대상: 사회 구성원
- 정렬 수단: 법률 명세 (legal spec)
AI 엔지니어
- 정렬 대상: 인공지능 모델
- 정렬 수단: 모델 명세 (model spec)
20분짜리 짧은 영상이였지만, 많은 내용이 담겨 있어 미처 담지 못한 내용들도 있습니다. 좋은 영상인 것 같아 직접 영상을 보시는 것도 추천드립니다.
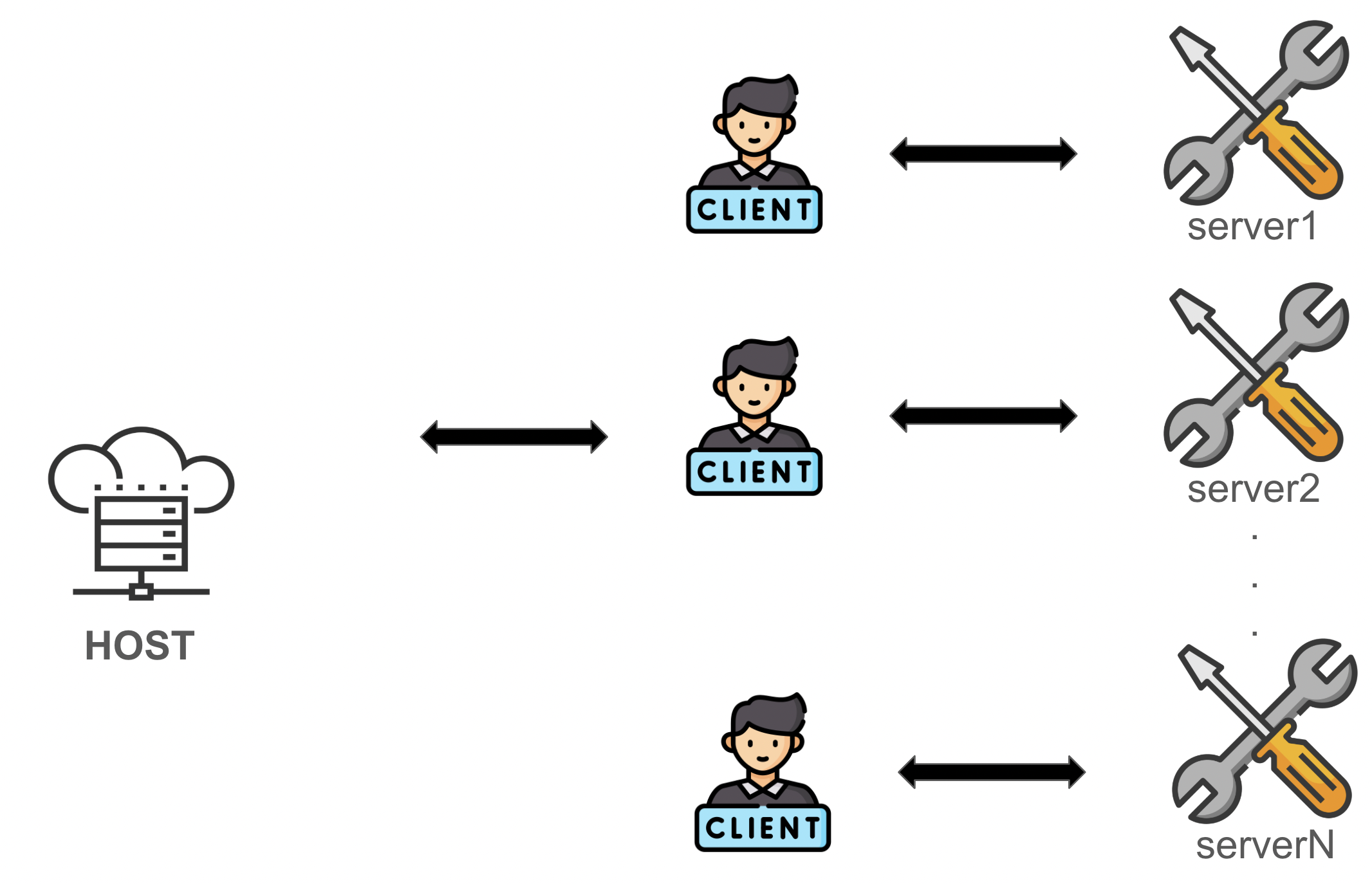
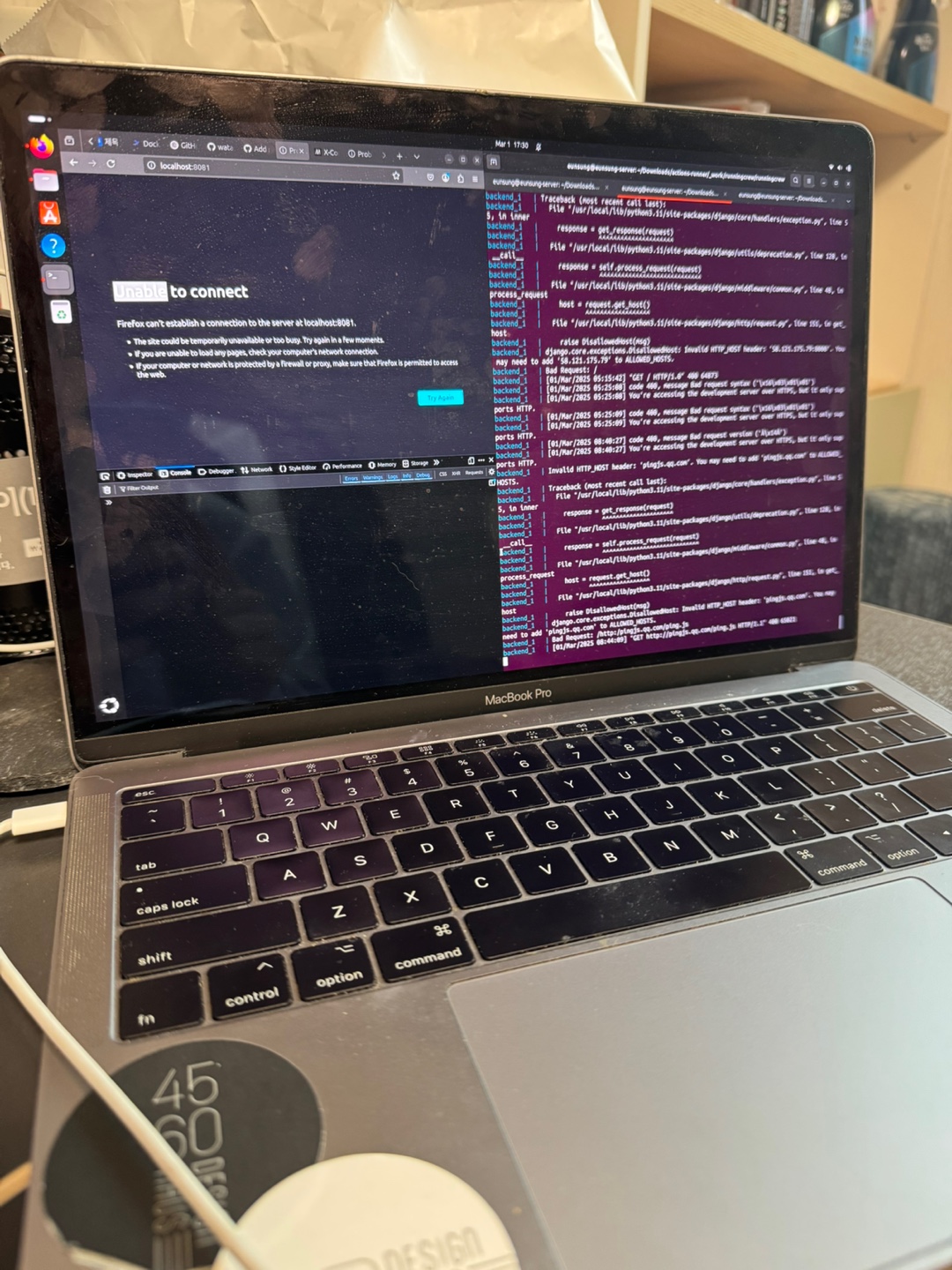
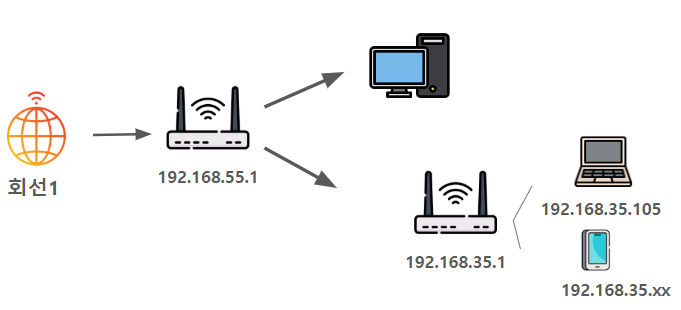
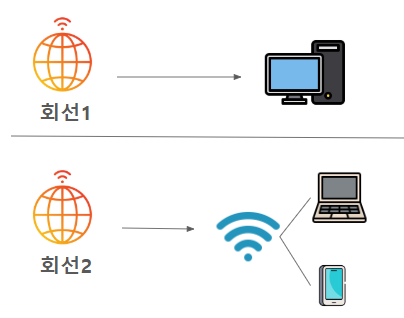
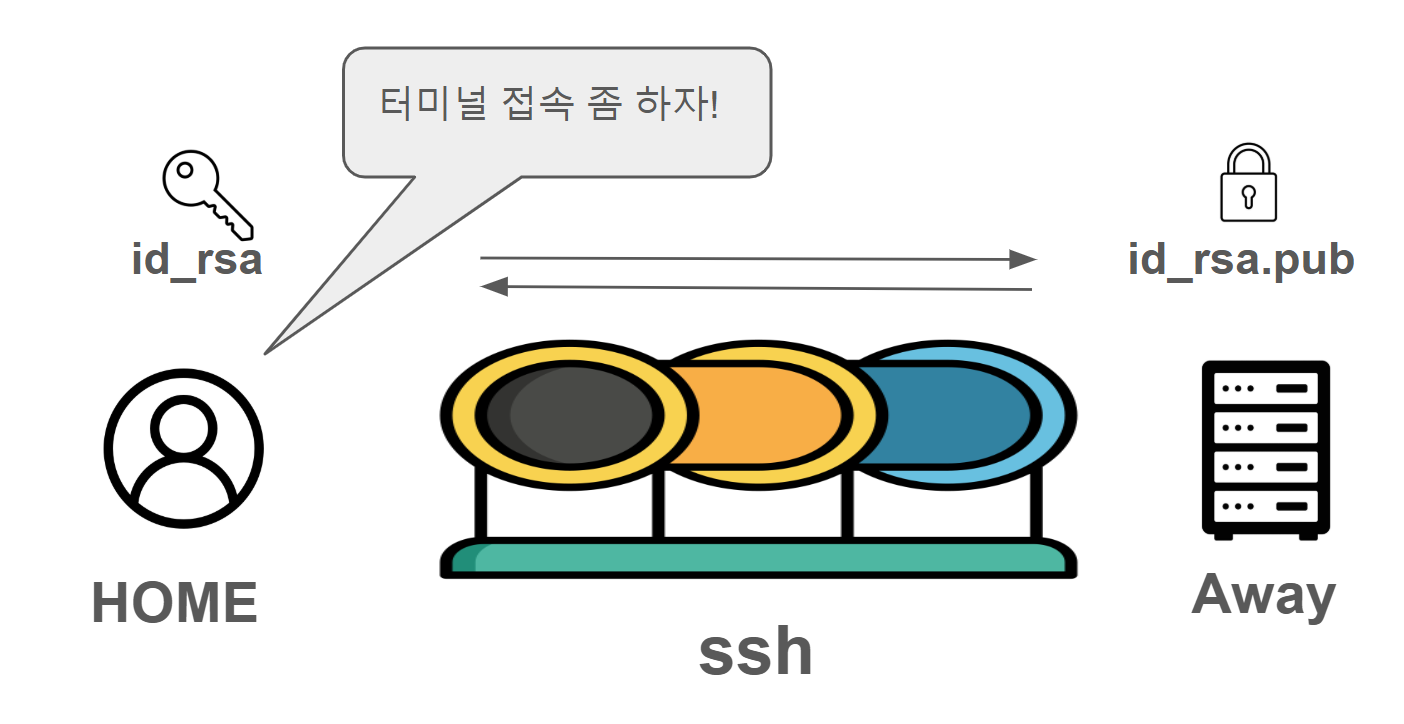 id_rsa를 발급받고 id_rsa.pub을 서버에 심는다. 그리고, 공유기 관리자 페이지에서 포트 포워딩을 해준다.
id_rsa를 발급받고 id_rsa.pub을 서버에 심는다. 그리고, 공유기 관리자 페이지에서 포트 포워딩을 해준다.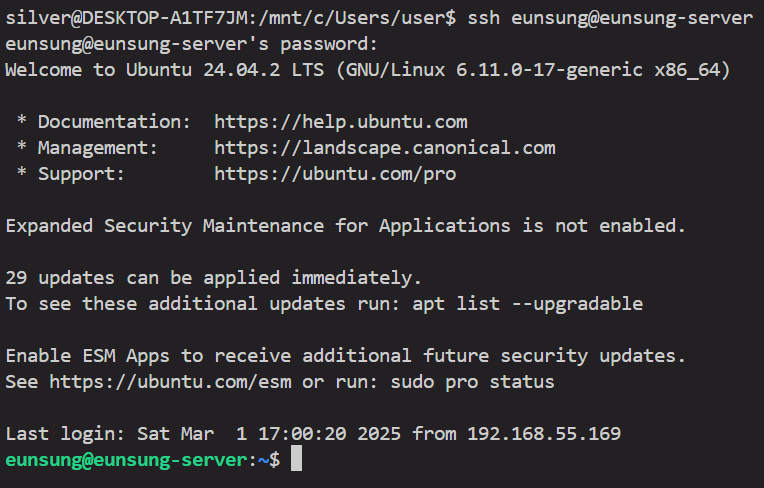 현재는 내부 네트워크에서 접속하는 거지만, 외부에서 접속하고 싶다면, 마찬가지로 ssh key를 발급받고, 서버에 심은 다음, 이전 글에서 설정한 dDNS 주소로 접속하면 된다.
현재는 내부 네트워크에서 접속하는 거지만, 외부에서 접속하고 싶다면, 마찬가지로 ssh key를 발급받고, 서버에 심은 다음, 이전 글에서 설정한 dDNS 주소로 접속하면 된다. 이제 이 서버(노트북이였던)는 더 이상 절전모드에 들어가지 않는다. 그리고 이어서 노트북 덮개를 덮어도 꺼지지 않도록 설정한다. etc 디렉토리의
이제 이 서버(노트북이였던)는 더 이상 절전모드에 들어가지 않는다. 그리고 이어서 노트북 덮개를 덮어도 꺼지지 않도록 설정한다. etc 디렉토리의 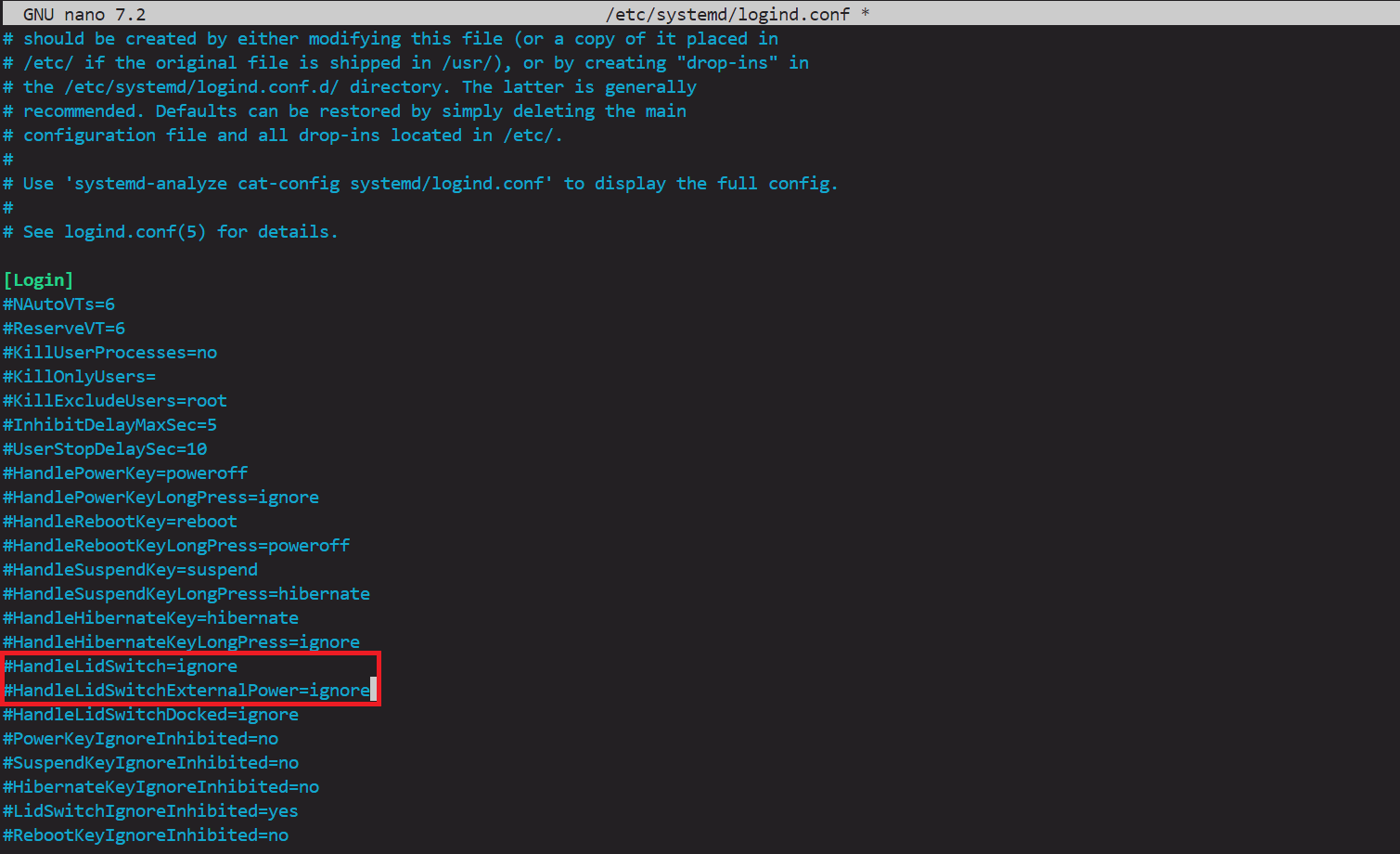



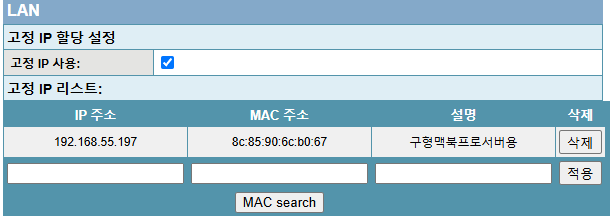
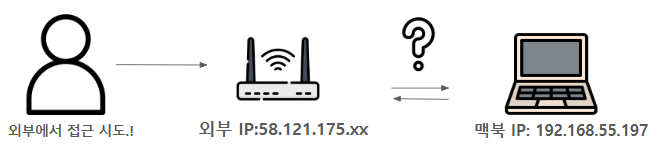
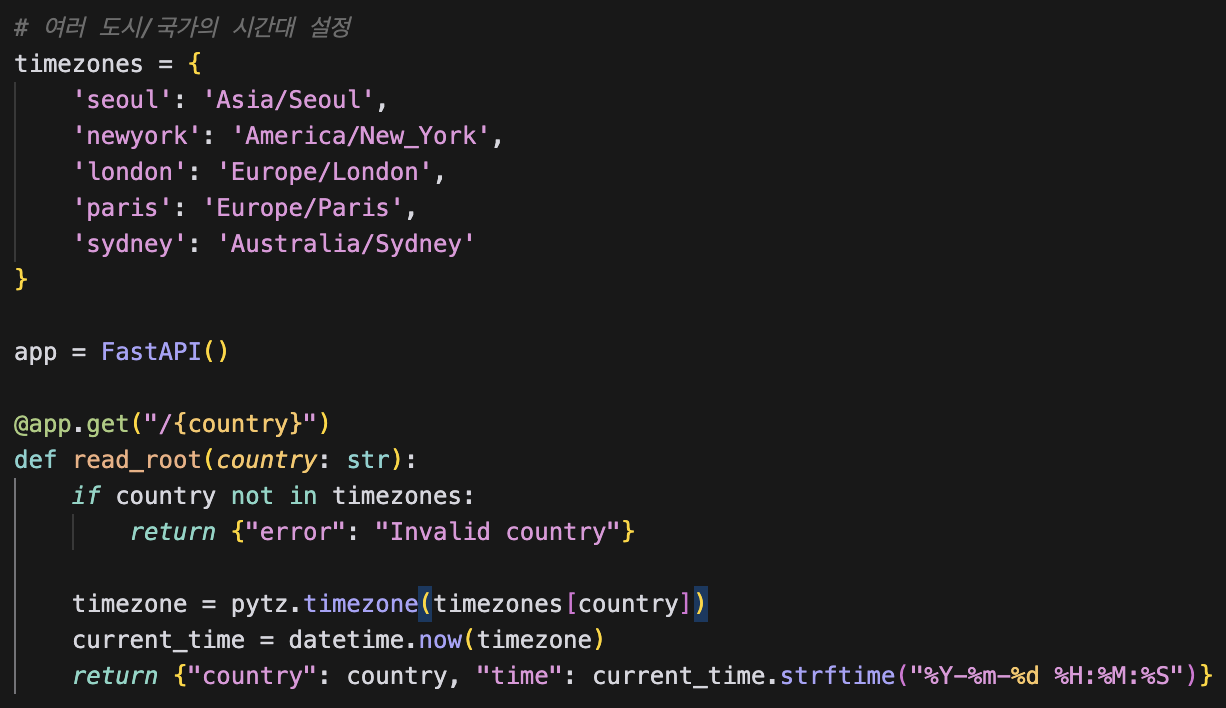





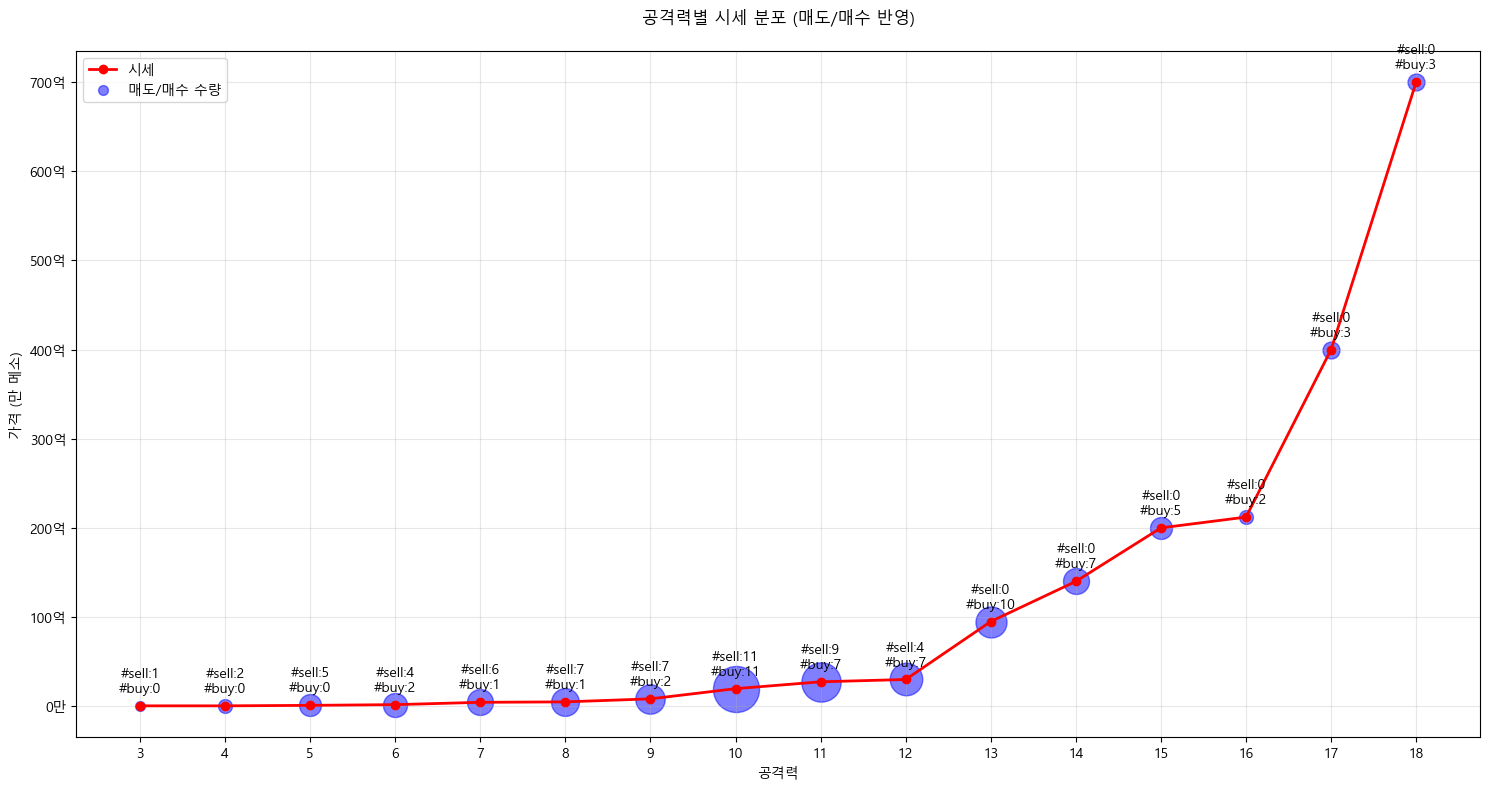

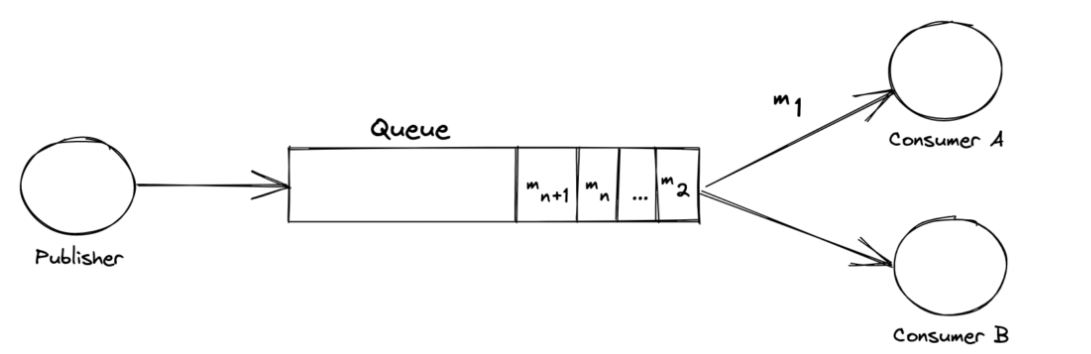
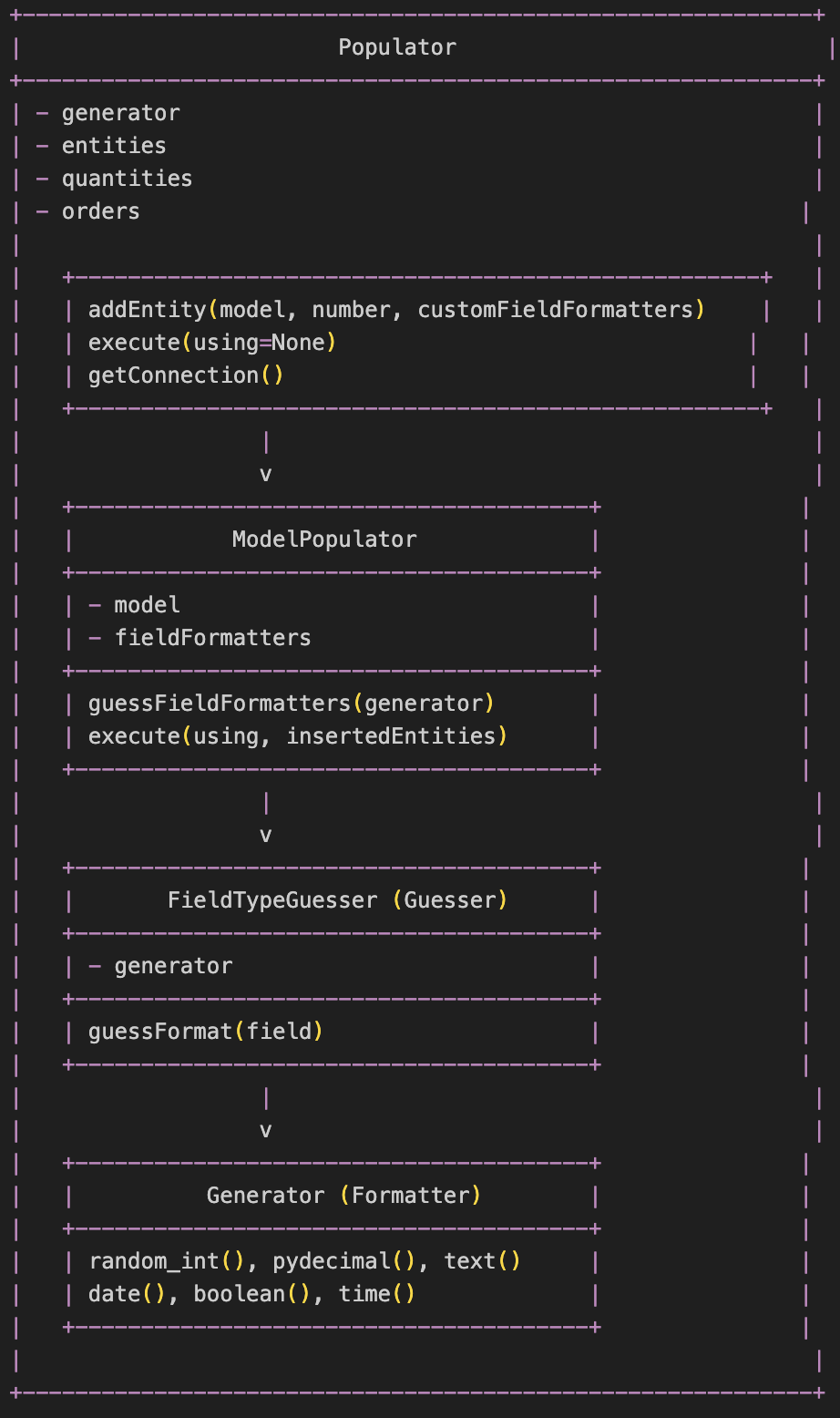

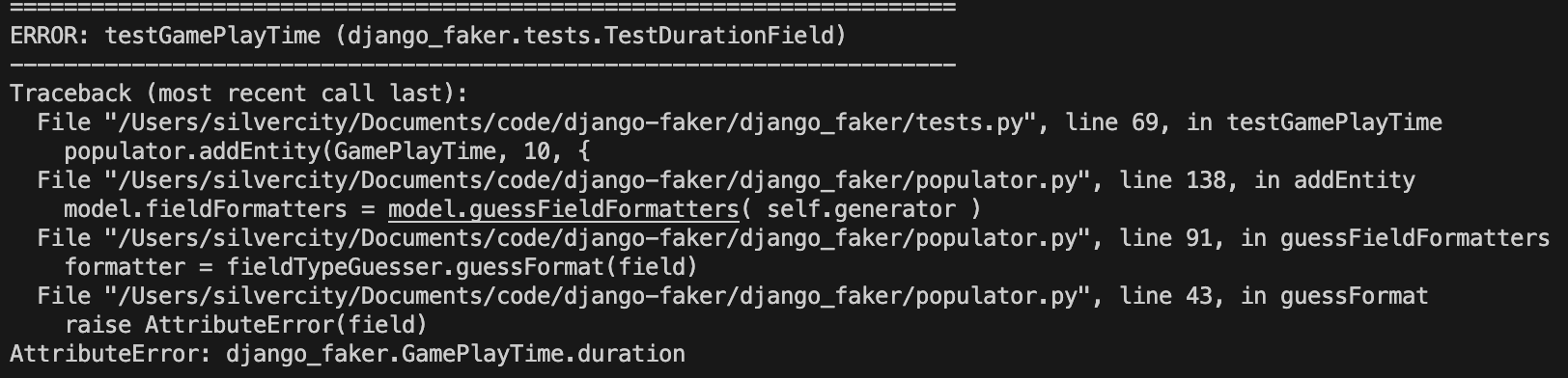
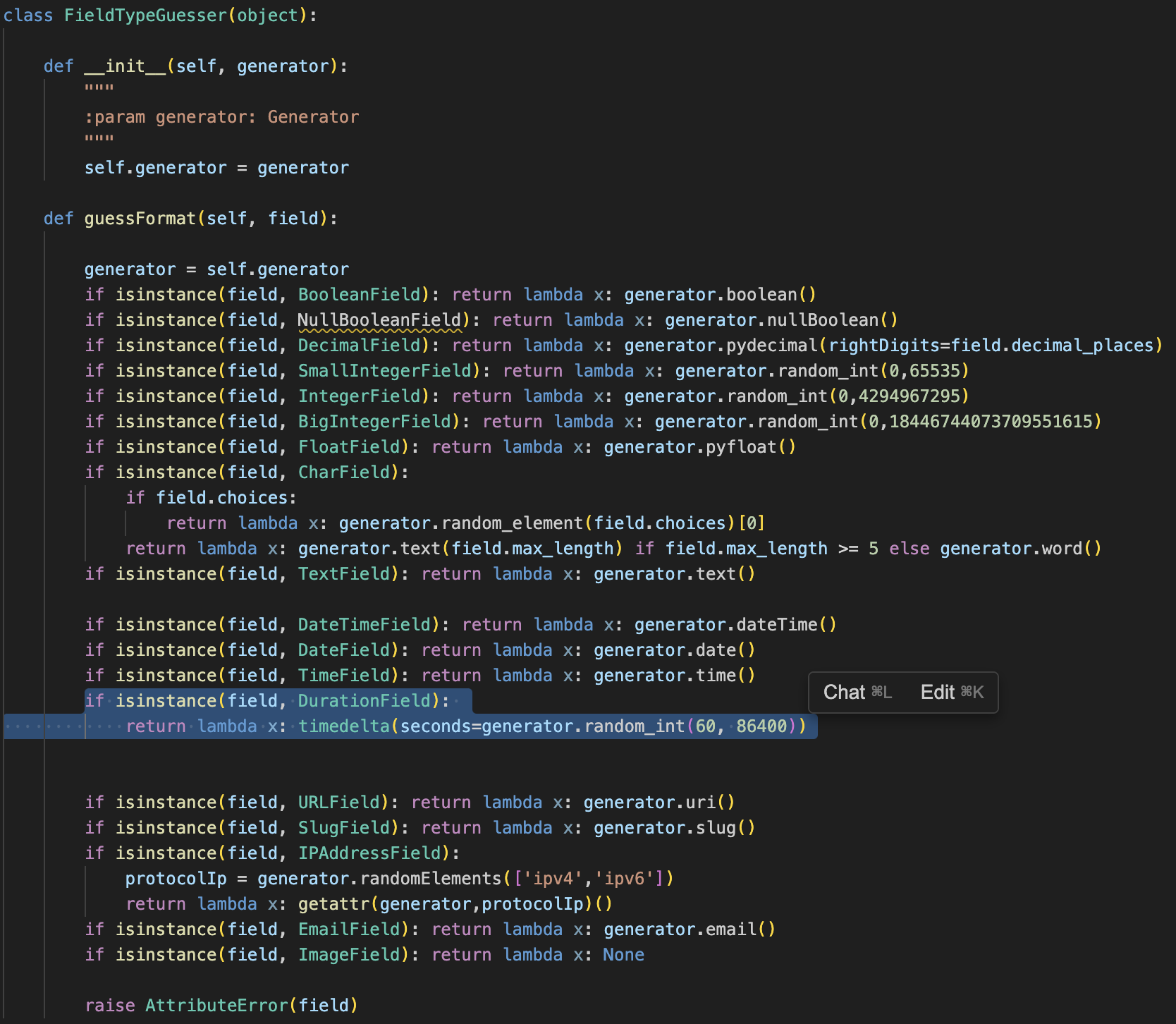 이렇게 작성한 코드를 바탕으로 테스트를 다시 실행시켜준다.
이렇게 작성한 코드를 바탕으로 테스트를 다시 실행시켜준다.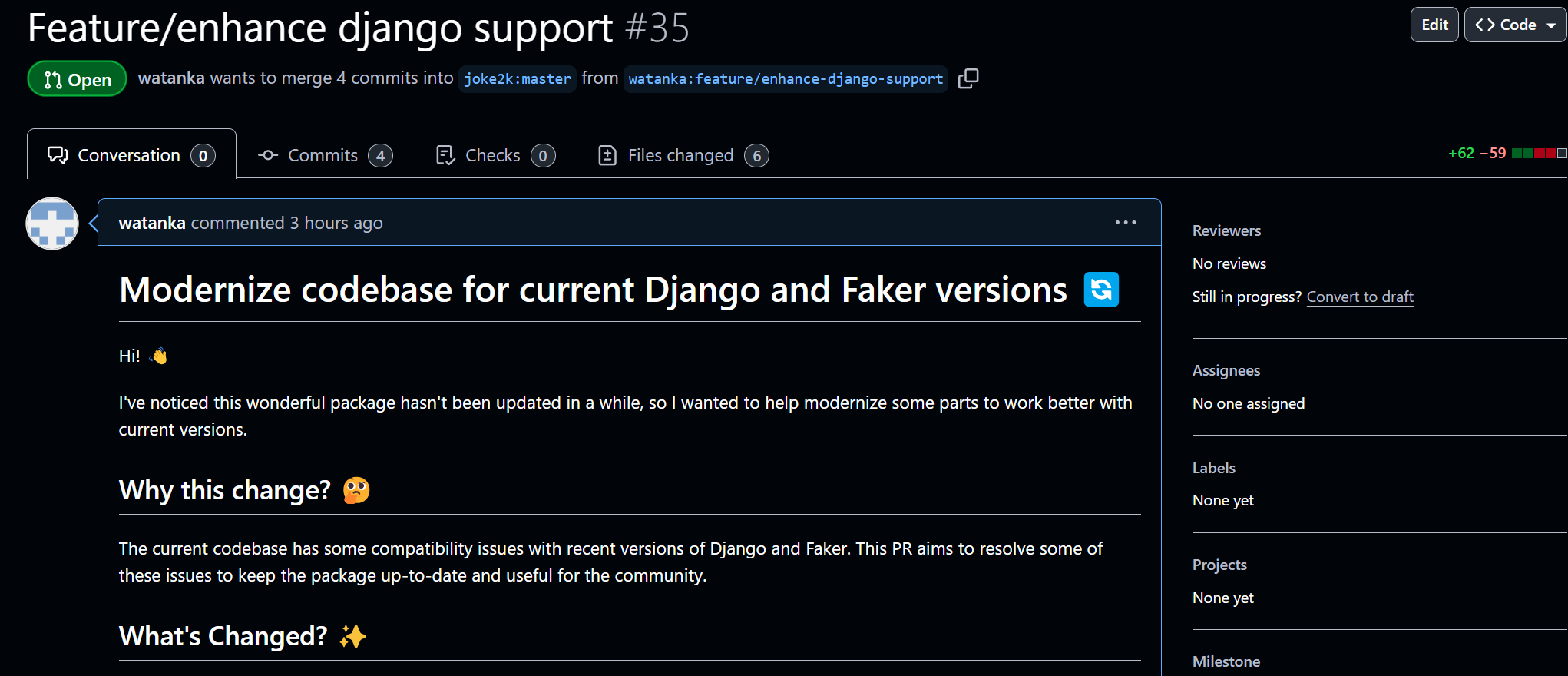

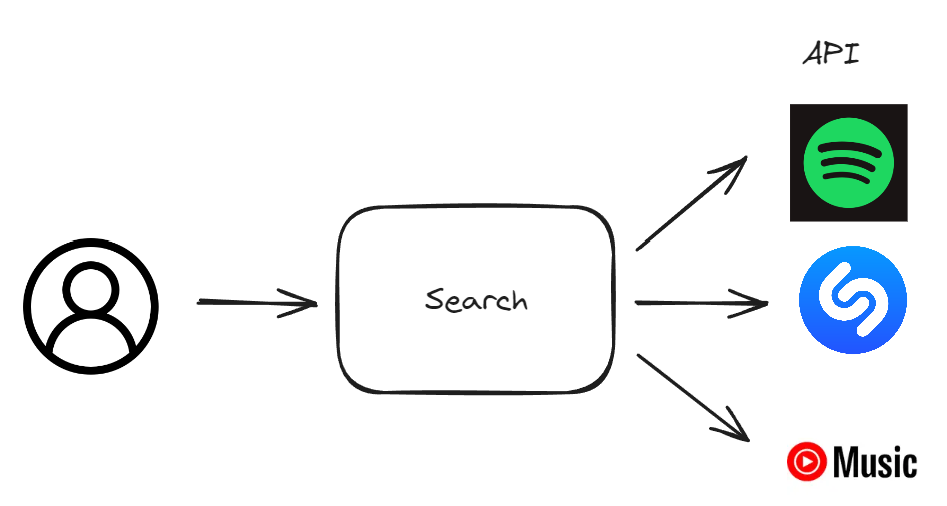 노래 검색을 위해 활용할 API가 세 개나 생겼다.
그럼 이제 들어오는 요청들을 이 API들에게 어떻게 분배해줄지 설정해주어야한다. 요구사항은
노래 검색을 위해 활용할 API가 세 개나 생겼다.
그럼 이제 들어오는 요청들을 이 API들에게 어떻게 분배해줄지 설정해주어야한다. 요구사항은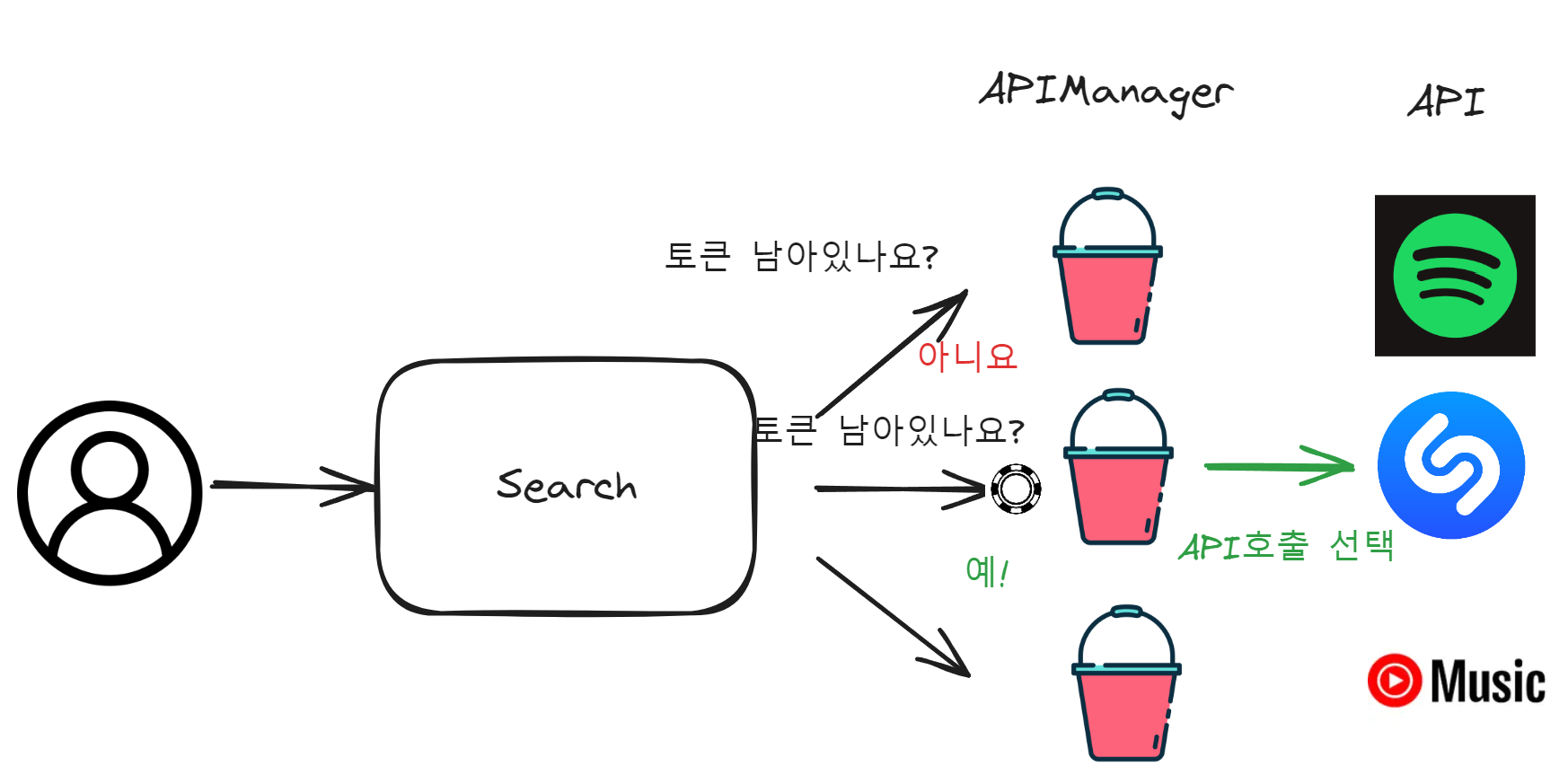
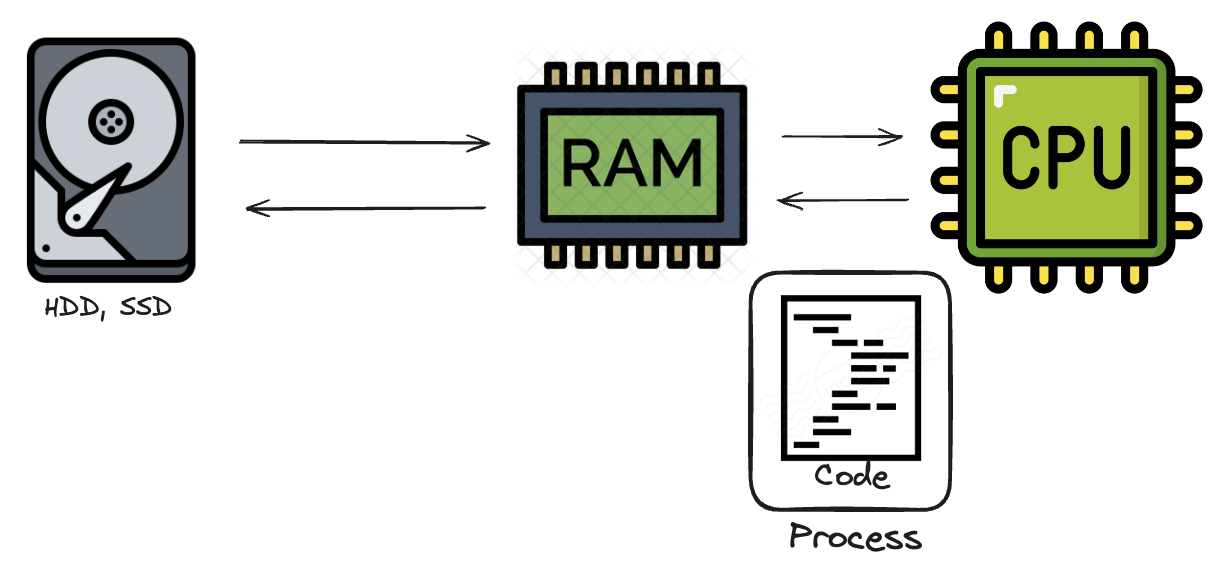 RAM에 적재된 코드는 컴퓨터가 이해할 수 있는 언어로 번역(소스코드 ->바이트코드->기계어)되어야합니다. 언어마다 다르지만, 파이썬은 작성한 코드를 메모리에 올릴 때마다 인터프리터가 코드 한줄 한줄 �이 번역을 수행해주는
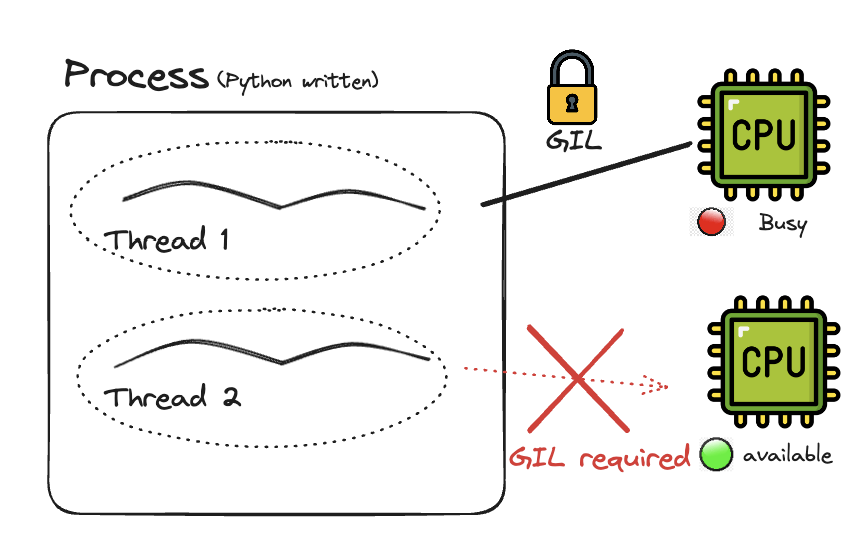
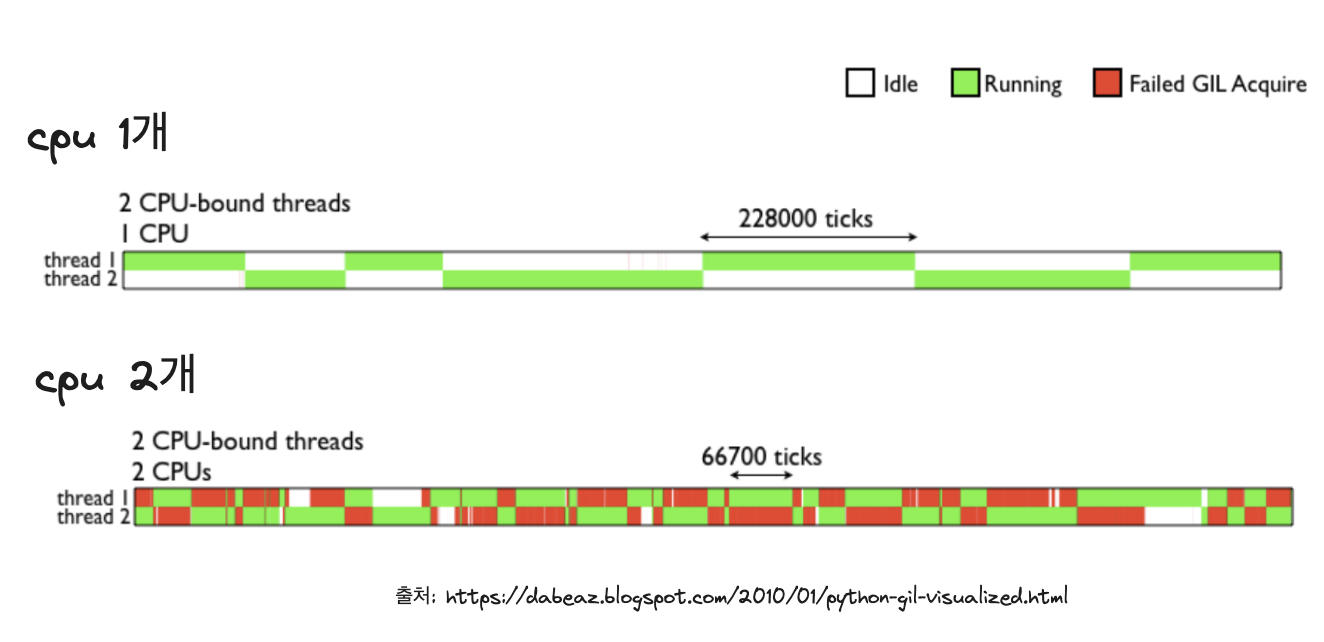
RAM에 적재된 코드는 컴퓨터가 이해할 수 있는 언어로 번역(소스코드 ->바이트코드->기계어)되어야합니다. 언어마다 다르지만, 파이썬은 작성한 코드를 메모리에 올릴 때마다 인터프리터가 코드 한줄 한줄 �이 번역을 수행해주는 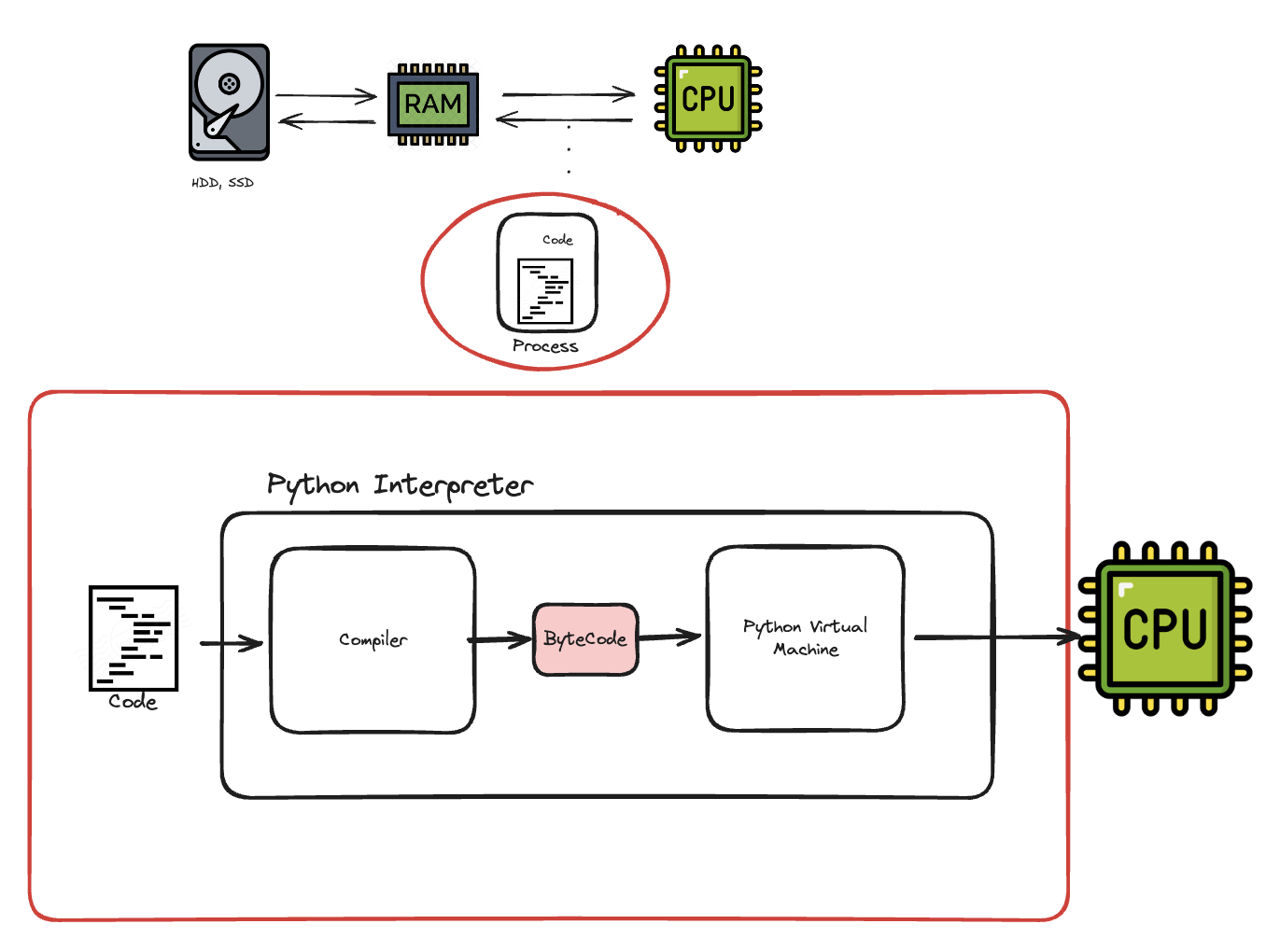 인터프리터는 사람이 작성한 코드를 CPU에서 수행할 수 있게 번역해주는 역할을 한다고 보면 됩니다. 그리고, GIL(Global Interpreter Lock)은 프로세스당 하나의 쓰레드만이 이 인터프리터의 제어권을 갖고 명령을 수행할 수 있게 하는 락(Mutex)입니다. 동일한 프로세스라면, 여러 쓰레드가 존재해도, 이 락을 소유하기 전까지는 명령을 수행할 수 없습니다.
GIL은 멀티코어로 구성되어있는 최근 CPU들을(2024년 기준 인텔 i7은 최대 20개의 코어, 애플 M3는 최대 40코어 보유) 멀티 쓰레딩으로 활용할 수 있는 이점을 제약합니다.
인터프리터는 사람이 작성한 코드를 CPU에서 수행할 수 있게 번역해주는 역할을 한다고 보면 됩니다. 그리고, GIL(Global Interpreter Lock)은 프로세스당 하나의 쓰레드만이 이 인터프리터의 제어권을 갖고 명령을 수행할 수 있게 하는 락(Mutex)입니다. 동일한 프로세스라면, 여러 쓰레드가 존재해도, 이 락을 소유하기 전까지는 명령을 수행할 수 없습니다.
GIL은 멀티코어로 구성되어있는 최근 CPU들을(2024년 기준 인텔 i7은 최대 20개의 코어, 애플 M3는 최대 40코어 보유) 멀티 쓰레딩으로 활용할 수 있는 이점을 제약합니다.
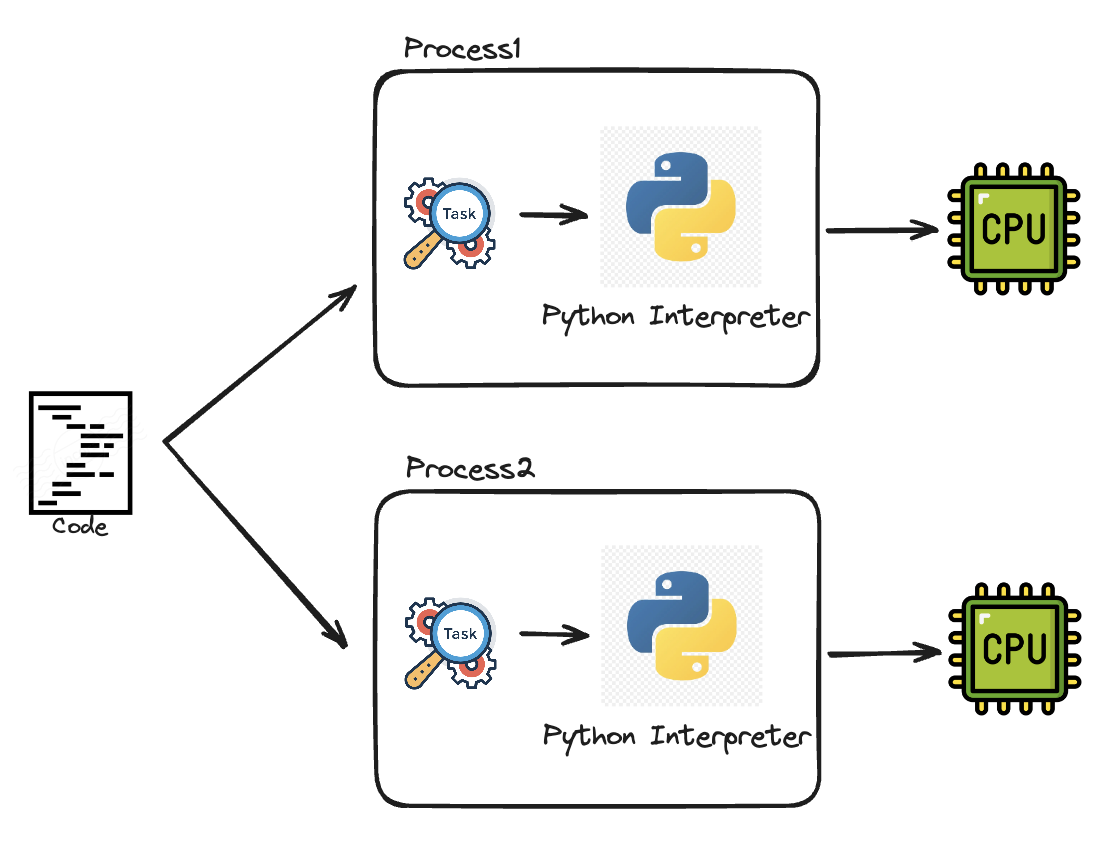 웹 게이트웨이 인터페이스인
웹 게이트웨이 인터페이스인